

L’intelligence artificielle générative est une technologie conçue pour produire des réponses en langage naturel, un peu comme si une machine pouvait “discuter” ou “écrire” de manière fluide. Pour y parvenir, l’IA s’appuie sur ce qu’on appelle des grands modèles de langage (LLM).
Ces modèles sont des systèmes qui ont été entraînés sur une énorme quantité de textes, comprenant des livres, des articles, des sites web, et bien d’autres sources d’information. L’objectif est d’apprendre à l’IA à reconnaître des schémas dans les phrases et à comprendre comment les mots s’associent pour former des idées cohérentes. Quand on lui pose une question, l’IA utilise ses connaissances pour formuler une réponse.
Cependant, une limite importante de cette technologie est que ses connaissances se basent uniquement sur des informations utilisées lors de l’entraînement du modèle. Il se peut que certaines informations plus récentes ne soient pas actualisées, donnant alors lieu à des réponses moins précises, ou tout simplement erronées.
C’est là qu’intervient la génération augmentée de récupération (RAG).
La RAG : qu’est ce que c’est ?
La génération augmentée de récupération est une méthode utilisée pour améliorer les réponses données par les grands modèles de langage, comme ceux utilisés dans les chatbots ou les assistants virtuels. Plutôt que de s’appuyer uniquement sur ce qu’ils savent, ces modèles peuvent aller chercher des informations actualisées et fiables dans une base de connaissances externe.
Imaginez une entreprise de voyage qui souhaite offrir à ses clients un chatbot capable de répondre aux questions sur les destinations, les offres et les services disponibles. Le chatbot doit être en mesure de fournir des informations sur les attractions locales, les types de transport, les options d’hébergement, ou encore des conseils de voyage. Un modèle de langage généraliste pourrait répondre à des questions générales, par exemple en expliquant les attractions principales d’une ville ou la meilleure période pour visiter un pays, puisqu’il connaît ces informations grâce à son entraînement initial..
Cependant, il ne pourrait pas répondre à des questions sur la météo locale de la semaine prochaine, les événements en cours ou les changements récents dans les restrictions de voyage. En effet, ce type d’information évolue rapidement, et le LLM ne peut pas s’adapter en temps réel car sa mise à jour nécessite des ressources de calcul importantes et un processus complexe.
Heureusement, l’entreprise de voyage possède déjà des sources de données actualisées, telles que les bases de données météorologiques, des flux d’actualités sur les conditions de voyage et les événements culturels, ainsi que les avis récents des voyageurs. Grâce à la RAG, l’IA générative peut consulter ces informations en temps réel et offrir des réponses plus précises et adaptées au contexte actuel de chaque demande
En résumé, la génération augmentée de récupération permet d’améliorer les réponses des LLM en intégrant des informations plus fraîches et contextuelles, pour une expérience utilisateur plus pertinente et complète.
Comment ça fonctionne ?
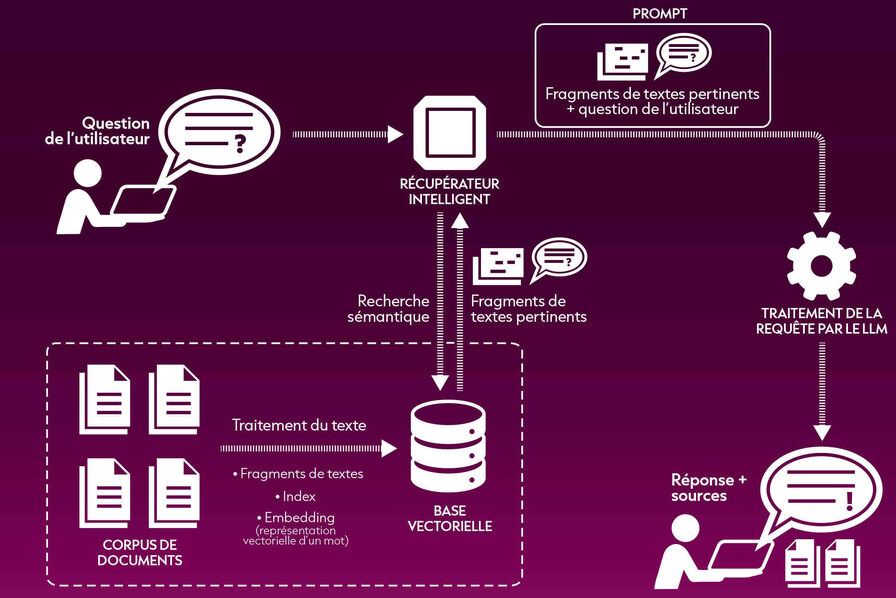
1. Le processus de récupération
Lorsqu’une requête est faite, la RAG identifie d’abord les documents ou données pertinents d’une base de données connectée. Cette étape est cruciale car elle détermine la qualité des informations qui viendront compléter la réponse générée par le modèle. Le processus de récupération implique des algorithmes sophistiqués conçus pour trier rapidement et précisément de grands volumes de données, garantissant que seules les informations les plus pertinentes sont utilisées.
2. Augmenter les LLMs avec des connaissances externes
Une fois les données pertinentes récupérées, elles sont alimentées dans le LLM, qui utilise ces informations pour générer une réponse. Ce processus d’augmentation permet au modèle d’incorporer des connaissances externes fraîches dans sa sortie, améliorant considérablement la pertinence et la précision de la réponse. Essentiellement, le LLM agit comme un moteur créatif, tandis que le système de récupération garantit que la sortie est ancrée dans la réalité.
3. Composants clés d’un système RAG
Un système RAG typique se compose de deux composants principaux : le récupérateur et le générateur. Le récupérateur est responsable de la recherche et de l’extraction d’informations pertinentes à partir de sources externes, tandis que le générateur utilise ces informations pour produire des réponses cohérentes et contextuellement appropriées. Ensemble, ces composants créent un système d’IA puissant capable de fournir un contenu très précis et pertinent.
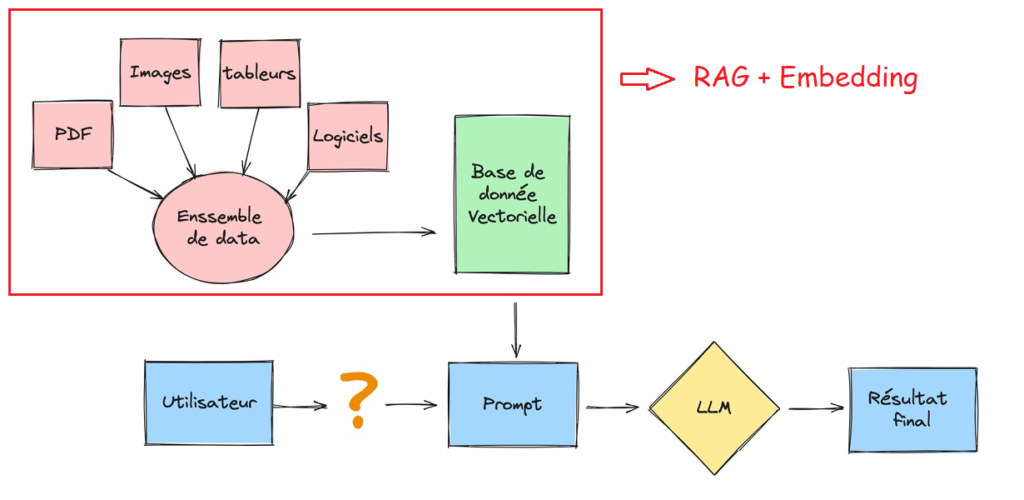
Les avantages de la RAG par rapport aux LLMs
La génération augmentée de récupération a plusieurs avantages par rapport aux modèles de langage qui fonctionnent de façon isolée. Voici plusieurs manières dont elle améliore la génération de texte et les réponses :
- La RAG s’assure que le modèle peut accéder aux derniers faits et informations les plus à jour, cela garantit que les réponses générées incorporent les dernières informations qui pourraient être pertinentes pour l’utilisateur qui réalise la requête.
- La RAG est une option plus rentable, car elle requiert moins d’informatique et de stockage, ce qui signifie que vous n’avez plus à posséder votre propre LLM ou à dépenser du temps et de l’argent à affiner le modèle.
- C’est une chose de revendiquer l’exactitude, mais encore faut-il la prouver ! La RAG peut citer ses sources externes et les fournir à l’utilisateur pour étayer ses réponses.
- Lorsqu’il est confronté à une requête complexe pour laquelle il n’a pas été entraîné, un LLM peut parfois “halluciner” et fournir une réponse inexacte. En fournissant une base solide à ses réponses grâce à des références supplémentaires, la RAG peut répondre de façon plus précise à des demandes ambiguës.
- Les modèles de RAG sont polyvalents et peuvent être appliqués à toute une gamme de tâches de traitement du langage naturel, y compris des systèmes de dialogue, de la génération de contenu ou de la récupération d’informations.
- Les partis pris peuvent être un problème dans de nombreuses IA créées par l’être humain. En se fiant à des sources externes approuvées, la RAG peut aider à diminuer les partis pris dans ses réponses.
Quelques cas d’usage concrets des modèles RAG
Afin de mieux illustrer les applications pratiques des modèles RAG, listons quelques exemples qui montrent comment cette technologie peut aider les entreprises dans différents domaines :
- Amélioration de l’assistance clientèle : Le modèle peut servir à créer des chatbots ou des assistants virtuels avancés qui répondent de manière plus personnalisée aux demandes des clients. Cela peut permettre de répondre plus rapidement, de gagner en efficacité opérationnelle et, en fin de compte, de rendre les clients plus satisfaits de leur expérience d’assistance.
- Génération de contenu : Le modèle RAG permet aux entreprises de produire des articles de blogs, des catalogues produits ou d’autres contenus en combinant leurs capacités génératives et d’extraction d’informations à partir de sources fiables, externes et internes.
- Réalisation des études de marché : Le modèle RAG, qui collecte des informations à partir des vastes volumes de données disponibles sur Internet (notamment les dernières nouvelles ou des publications sur les réseaux sociaux), permet aux entreprises de se tenir au courant des tendances du marché, d’analyser les activités de leurs concurrents, et ainsi de prendre des décisions plus éclairées.
- Assistance dans les ventes : Le modèle RAG peut servir d’assistant commercial virtuel, c’est-à-dire répondre aux questions des clients sur les articles en stock, extraire des spécifications produits, expliquer des modes d’emploi et, plus généralement, participer au cycle d’achat. Il peut combiner ses capacités génératives avec des catalogues produits, des informations sur les prix, pour faire des recommandations personnalisées et répondre aux préoccupations des clients.
- Amélioration de l’expérience des employés : Le modèle RAG peut permettre aux employés de créer et de partager un référentiel centralisé de connaissances spécialisées. Le modèle s’intègre aux bases de données et aux documents internes, et fournit aux employés des réponses précises aux questions qu’ils se posent sur les activités de l’entreprise, les avantages, les processus, la culture, la structure organisationnelle etc.
Défis liés à la génération augmentée par récupération
Introduite seulement en 2020, La RAG est une technologie encore en évolution. Les développeurs d’IA travaillent à perfectionner les mécanismes de récupération d’informations pour optimiser son intégration dans les systèmes d’IA générative, mais cela pose encore de nombreux défis :
- Renforcement des connaissances et de la compréhension : Étant une technologie récente, elle nécessite que les entreprises acquièrent des compétences spécifiques pour bien l’implémenter et l’utiliser de manière optimale.
- Coûts accrus : Mettre en place la RAG implique des coûts initiaux plus élevés comparés à un modèle de langage seul. Cependant, à long terme, cette solution est plus avantageuse, car elle permet de réduire la fréquence des réentraînements du modèle principal.
- Modélisation des données non structurées : Pour que la RAG soit efficace, il est essentiel d’organiser correctement les données sous des formats variés (textes, images, bases de données, etc.) au sein de la bibliothèque de connaissances et de la base de données vectorielle.
- Intégration progressive des données : La mise en œuvre de la RAG nécessite de développer des processus permettant d’ajouter des données de manière continue et contrôlée afin de garder les informations toujours à jour.
- Mise en place de processus de correction : Il est indispensable d’élaborer des méthodes pour identifier, corriger ou supprimer les informations incorrectes, afin que le système RAG maintienne une base de données fiable et évite les hallucinations.
Différence entre génération augmentée de récupération et recherche sémantique
Les entreprises modernes stockent une grande quantité d’informations, comme des manuels, des FAQ, des rapports de recherche, des guides de service client, et des documents RH, sur divers systèmes. À grande échelle, récupérer le contexte pertinent devient complexe, ce qui peut réduire la qualité des réponses générées.
Grâce aux technologies de recherche sémantique, il est possible d’analyser efficacement des bases de données massives contenant des informations variées et de récupérer les données de manière plus précise. Par exemple, elles peuvent répondre à une question comme « Combien a-t-on consacré à la réparation de machines l’année dernière ? » en alignant la question sur les documents pertinents et en fournissant une réponse spécifique, au lieu d’une simple liste de résultats de recherche.
Les solutions traditionnelles, basées sur des recherches par mots-clés, génèrent souvent des résultats insuffisants pour les tâches nécessitant une forte densité de connaissances. De plus, les développeurs doivent encore gérer l’intégration de termes, le découpage des documents et d’autres complexités lors de la préparation manuelle des données.
À l’inverse, les technologies de recherche sémantique prennent en charge l’organisation et l’optimisation de la base de connaissances, ce qui évite aux développeurs de le faire manuellement. Elles produisent également des extraits sémantiquement pertinents mais aussi des mots-clés classés par pertinence, maximisant la qualité des réponses générées.
Conclusion
Pour les entreprises modernes, adopter la génération augmentée de récupération est devenu essentiel pour maintenir une compétitivité fondée sur des réponses pertinentes et actualisées. En intégrant des données externes aux modèles de langage, la RAG dépasse les limitations des LLM classiques et renforce la pertinence et la précision des interactions utilisateur.
Grâce à cette capacité de récupération en temps réel, les entreprises peuvent offrir des expériences personnalisées, améliorer la satisfaction client, accéder à des insights stratégiques, tout en réduisant les coûts de mise à jour des modèles.
La RAG se profile ainsi comme une technologie clé pour les applications d’intelligence artificielle du futur, offrant aux organisations la flexibilité nécessaire pour s’adapter aux évolutions constantes du marché et aux attentes des utilisateurs.



