

Définition du Natural Language Processing (NLP)
Le Natural Language Processing est une branche de l’intelligence artificielle qui se concentre sur l’interaction entre les ordinateurs et les humains en utilisant le langage naturel. L’objectif principal du NPL est de permettre aux machines de comprendre, interpréter et générer du texte de manière à imiter la compréhension humaine. Il est utilisé pour générer des réponses dans des systèmes de dialogue type chatbots, mais aussi pour rédiger des articles ou des rapports automatiquement.
Afin de permettre cette compréhension et manipulation efficace du texte par les machines, il est nécessaire de convertir les mots en une forme que les algorithmes peuvent traiter. C’est ici qu’intervient l’une des techniques les plus importantes du NLP : l’embedding.
Comprendre l’embedding dans le traitement du langage naturel
L’embedding est une technique fondamentale en traitement du langage naturel. Elle permet de transformer des mots, des phrases ou même des documents entiers en vecteurs de nombres, facilitant ainsi leur manipulation par des modèles d’apprentissage automatique.
L’embedding peut être vu comme un réseau de neurones qui capture le sens du texte à l’intérieur d’une série de chiffres sous forme de vecteurs dans un espace multidimensionnel. Ces vecteurs capturent la sémantique des mots, de sorte que des mots de sens similaires seront proches les uns des autres dans cet espace vectoriel. Si on imagine un nuage de points, cela veut dire que les points qui représentent un texte similaire vont être prêts les uns des autres alors que les coordonnées de textes dissimilaires vont être éloignées.
Avantages et améliorations
- Grâce aux techniques d’embedding, la vie des grands modèles de langage (LLM) est simplifiée quand vient le temps de faire une recherche : tout ce qu’ils doivent faire, c’est trouver la position de la requête de recherche dans le nuage de points et de prendre ses voisins comme réponses ! Cette technique améliore significativement la précision et la pertinence des réponses générées. En utilisant des embeddings, les modèles peuvent saisir les nuances sémantiques et contextuelles des mots, ce qui leur permet de comprendre le véritable sens derrière une requête.
- Les embeddings permettent également de surmonter les défis des synonymes et des variations linguistiques. Par exemple, des mots comme “automobile” et “voiture” seront positionnés proches l’un de l’autre dans l’espace vectoriel, ce qui permet au moteur de recherche de retourner des résultats pertinents même si les termes exacts ne sont pas utilisés dans la requête. De plus, les embeddings peuvent gérer les ambiguïtés contextuelles, distinguant par exemple le mot “batterie” utilisé pour la musique et pour un appareil électronique, en fonction des mots environnants dans la phrase.
- Un autre avantage clé des embeddings est leur capacité à traiter des requêtes plus longues et complexes. Plutôt que de simplement faire correspondre les mots-clés, les moteurs de recherche utilisant des embeddings peuvent comprendre le contexte global de la phrase ou du paragraphe de la requête. Par exemple, une requête complexe comme “meilleurs endroits pour des vacances en famille avec des activités pour enfants” sera mieux comprise et traitée, car les embeddings peuvent capturer les relations entre les concepts de “vacances”, “famille”, et “activités pour enfants”.
- Les embeddings facilitent enfin l’intégration de la recherche multilingue. Comme ils peuvent être appris sur des corpus multilingues, il est possible de faire correspondre des requêtes et des documents de différentes langues dans un espace vectoriel commun. Cela signifie qu’une requête en anglais pourrait trouver des documents pertinents en français, en espagnol, ou dans toute autre langue supportée, augmentant ainsi l’accessibilité et la portée des moteurs de recherche.

Méthodes de Création d’Embeddings
Il existe plusieurs méthodes pour créer des embeddings. Voici un aperçu des principales :
- One Hot Encoding : Chaque mot du vocabulaire est représenté par un vecteur binaire unique. Cette méthode, bien que simple, ne capture pas les relations sémantiques entre les mots.
- Word2Vec : Cette technique utilise des réseaux de neurones pour apprendre les représentations vectorielles des mots en fonction de leur contexte dans de grands corpus de texte. Il existe deux variantes principales : Continuous Bag of Words (CBOW) et Skip-Gram.
- GloVe (Global Vectors for Word Representation) : Développée par des chercheurs de Stanford, cette méthode combine les avantages de la factorisation de matrice et des techniques basées sur le contexte local des mots.
Applications des Embeddings
Les embeddings sont utilisés dans une variété d’applications :
- Recherche d’informations : Dans les moteurs de recherche modernes, les embeddings permettent de comprendre le sens des requêtes et de retourner des résultats plus pertinents.
- Systèmes de recommandation : Ils sont utilisés pour représenter les utilisateurs et les articles dans un espace vectoriel commun, facilitant ainsi les recommandations personnalisées. Par exemple, Netflix utilise des embeddings pour recommander des films et des séries télévisées en fonction de l’historique de visionnage des utilisateurs.
- Traitement du Langage Naturel (TAL) : Les embeddings de mots sont essentiels pour des tâches telles que l’analyse de sentiments, la traduction automatique, et la compréhension du langage naturel. Ils permettent aux modèles de capturer des nuances sémantiques et syntaxiques importantes.
Implémentation pratique
Voici une explication détaillée des trois principales étapes de cette implémentation :
1. Vectorisation du Corpus :
La première étape consiste à transformer le texte en une séquence d’entiers, où chaque entier représente un mot spécifique dans le vocabulaire du corpus. Cette étape est essentielle pour convertir les données textuelles en un format numérique que les modèles de machine learning peuvent traiter.
- Construction du vocabulaire : On commence par analyser l’ensemble du corpus de texte pour construire un vocabulaire, c’est-à-dire une liste de tous les mots uniques présents dans le texte.
- Assignation d’index : Chaque mot du vocabulaire est ensuite associé à un entier unique. Par exemple, le mot “chat” pourrait être représenté par l’entier 1, “chien” par 2, etc.
- Transformation en séquence d’entiers : Chaque document ou phrase du corpus est transformé en une séquence d’entiers en remplaçant chaque mot par son index correspondant. Par exemple, la phrase “le chat est mignon” pourrait être transformée en [3, 1, 4, 5], où chaque entier correspond à un mot du vocabulaire.
2. Utilisation d’une couche d’embedding :
La deuxième étape consiste à convertir ces séquences d’entiers en vecteurs d’embeddings. Cela se fait à l’aide d’une couche d’embedding dans le modèle de traitement du langage.
- Matrice d’Embedding : Une matrice d’embedding est créée, où chaque ligne représente le vecteur d’embedding d’un mot spécifique du vocabulaire. Cette matrice peut être initialisée aléatoirement ou pré-entraînée à partir de modèles existants comme Word2Vec, GloVe, ou FastText.
- Mapping des entiers : Lors de l’entraînement, chaque entier de la séquence est utilisé pour indexer la matrice d’embedding et récupérer le vecteur d’embedding correspondant. Par exemple, si “chat” est représenté par 1, alors le vecteur d’embedding associé à “chat” sera la première ligne de la matrice.
- Transformation en vecteurs : La séquence d’entiers est ainsi transformée en une séquence de vecteurs d’embeddings. Si la phrase “le chat est mignon” est représentée par [3, 1, 4, 5], alors elle est convertie en une séquence de vecteurs d’embeddings, chacun ayant une dimension prédéfinie.
3. Entraînement du Modèle :
La dernière étape consiste à utiliser ces embeddings dans un modèle de classification ou de prédiction. Au cours de l’entraînement, les poids de la matrice d’embedding sont ajustés pour améliorer la performance du modèle.
- Intégration dans le modèle : Les vecteurs d’embeddings sont utilisés comme entrées pour le modèle de traitement du langage naturel, qui peut être un réseau de neurones récurrent (RNN), un réseau de neurones convolutionnel (CNN), ou un transformeur.
- Propagation avant : Les vecteurs d’embeddings passent à travers les différentes couches du modèle pour produire des prédictions. Par exemple, dans une tâche de classification de texte, le modèle pourrait prédire la catégorie d’un document.
- Calcul de la perte : La perte (ou erreur) entre les prédictions du modèle et les vraies étiquettes est calculée.
- Rétropropagation : Le modèle ajuste les poids de toutes ses couches, y compris la matrice d’embedding, pour minimiser la perte. Ce processus de rétropropagation permet d’affiner les vecteurs d’embeddings pour qu’ils capturent mieux les relations sémantiques spécifiques à la tâche.
Grâce à ces ajustements, les embeddings deviennent de plus en plus représentatifs des données et des relations contextuelles, améliorant ainsi les performances du modèle sur la tâche donnée. Un défi majeur dans leur utilisation est leur application dans la recherche d’information en temps réel. Pour répondre efficacement à une requête, il faut être capable de scanner et d’indexer de grandes quantités de données rapidement.
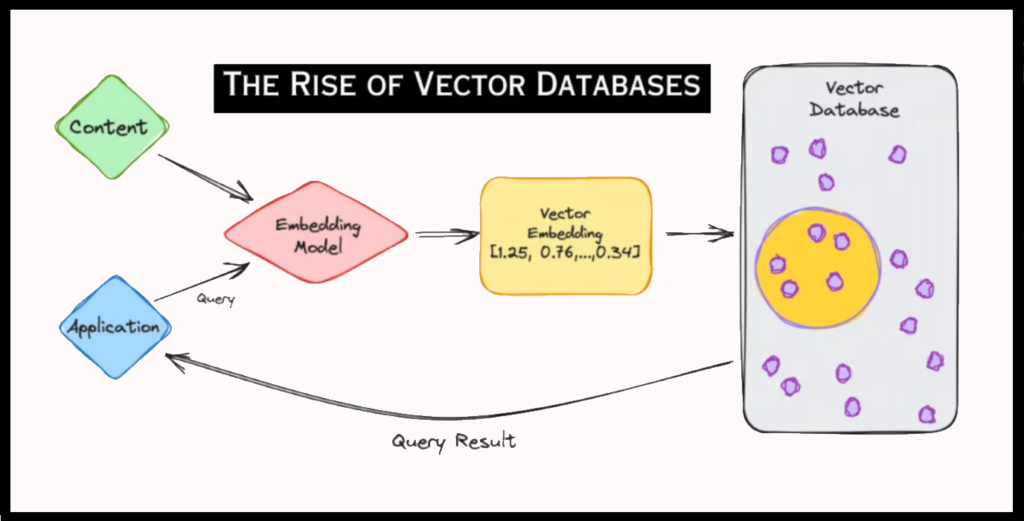
Utilisation d’Embeddings pour les Chatbots
Les embeddings permettent également de construire des chatbots plus intelligents et pertinents. En les intégrant dans des systèmes de dialogue, il est possible de fournir des réponses contextuelles basées sur l’ensemble des interactions précédentes et des informations disponibles.
Par exemple, si un utilisateur pose une question sur une politique de remboursement après avoir discuté d’une commande spécifique, le chatbot peut utiliser les embeddings pour relier cette question à la commande en question et fournir une réponse précise et contextuelle.
De plus, en utilisant une base de données vectorielle, le chatbot peut rapidement rechercher et comparer les embeddings des questions avec ceux des documents indexés, trouvant ainsi les réponses les plus pertinentes même en cas de variations linguistiques. Cette approche permet une compréhension plus profonde et une interaction plus fluide entre l’utilisateur et le chatbot.
Enfin, le fine-tuning des modèles pré-entraînés permet d’optimiser davantage les performances des systèmes d’IA en adaptant les embeddings à des tâches spécifiques.
Synthèse
L’embedding est une technique puissante et polyvalente en intelligence artificielle. Il permet de transformer des données discrètes en représentations vectorielles continues, facilitant la manipulation et l’interprétation des informations par les modèles d’IA.
Que ce soit dans le traitement du langage naturel, les systèmes de recommandation ou la recherche d’information, les embeddings jouent un rôle crucial et ouvrent la voie à des applications toujours plus avancées et performantes.En comprenant et en maîtrisant les embeddings, les entreprises peuvent développer des systèmes d’IA plus intelligents et répondre de manière pertinente à une multitude de requêtes. Au cœur de l’intelligence artificielle moderne, il ne fait aucun doute que les embeddings continueront à être un domaine de recherche et d’innovation clé dans les années à venir.



