

Definition of Natural Language Processing (NLP)
Natural Language Processing (NLP) is a branch of artificial intelligence focused on the interaction between computers and humans using natural language. The primary goal of NLP is to enable machines to understand, interpret, and generate text in a way that mimics human comprehension. It is used for generating responses in dialogue systems like chatbots and for automatically drafting articles or reports.
To allow machines to effectively understand and manipulate text, it’s necessary to convert words into a form that algorithms can process. This is where one of the most crucial NLP techniques comes into play: embedding.
Understanding Embedding in Natural Language Processing
Embedding is a fundamental technique in NLP, which transforms words, phrases, or even entire documents into numerical vectors, making them easier for machine learning models to handle.
An embedding can be viewed as a neural network that captures the meaning of the text within a series of numbers, represented as vectors in a multidimensional space. These vectors capture the semantics of words, ensuring that words with similar meanings are located near each other in the vector space. Imagine a cloud of points: similar texts are represented by points close to each other, while dissimilar texts are located farther apart.
Advantages and Enhancements
- Thanks to embedding techniques, the life of large language models (LLMs) is simplified when it comes to search tasks: all they need to do is find the position of the search query in the point cloud and select its neighbors as answers! This technique significantly improves the accuracy and relevance of generated responses. By using embeddings, models can grasp the semantic and contextual nuances of words, allowing them to understand the true meaning behind a query.
- Embeddings also help overcome challenges related to synonyms and linguistic variations. For instance, words like “automobile” and “car” will be positioned close to each other in the vector space, enabling the search engine to return relevant results even if the exact terms aren’t used in the query. Moreover, embeddings can handle contextual ambiguities, distinguishing between words like “battery” in a musical context versus an electronic device, based on surrounding words in the sentence.
- Another key advantage of embeddings is their ability to process longer and more complex queries. Instead of merely matching keywords, search engines using embeddings can understand the overall context of the phrase or paragraph in the query. For example, a complex query like “best places for family vacations with activities for children” will be better understood and processed, as embeddings can capture the relationships between concepts like “vacation,” “family,” and “children’s activities.”
- Finally, embeddings facilitate the integration of multilingual search. Since they can be trained on multilingual corpora, it’s possible to match queries and documents from different languages within a common vector space. This means a query in English could find relevant documents in French, Spanish, or any other supported language, thus increasing the accessibility and reach of search engines.

Methods of Creating Embeddings
There are several methods to create embeddings. Here is an overview of the main ones:
- One Hot Encoding: Each word in the vocabulary is represented by a unique binary vector. This method, though simple, does not capture semantic relationships between words.
- Word2Vec: This technique uses neural networks to learn vector representations of words based on their context in large text corpora. There are two main variants: Continuous Bag of Words (CBOW) and Skip-Gram.
- GloVe (Global Vectors for Word Representation): Developed by researchers at Stanford, this method combines the advantages of matrix factorization and context-based techniques for word representation.
Applications of Embeddings
Embeddings are used in a variety of applications:
- Information Retrieval: In modern search engines, embeddings help understand the meaning of queries and return more relevant results.
- Recommendation Systems: They are used to represent users and items in a common vector space, facilitating personalized recommendations. For instance, Netflix uses embeddings to recommend movies and TV shows based on users’ viewing history.
- Natural Language Processing (NLP): Word embeddings are essential for tasks such as sentiment analysis, machine translation, and natural language understanding. They allow models to capture important semantic and syntactic nuances.
Practical Implementation
Here is a detailed explanation of the three main steps in this implementation:
1. Corpus Vectorization:
The first step involves transforming the text into a sequence of integers, where each integer represents a specific word in the corpus vocabulary. This step is crucial for converting textual data into a numerical format that machine learning models can process.
- Vocabulary Construction: Begin by analyzing the entire text corpus to build a vocabulary, which is a list of all unique words in the text.
- Index Assignment: Each word in the vocabulary is then associated with a unique integer. For example, the word “cat” might be represented by the integer 1, “dog” by 2, etc.
- Transformation into Integer Sequences: Each document or sentence in the corpus is transformed into a sequence of integers by replacing each word with its corresponding index. For instance, the phrase “the cat is cute” could be transformed into [3, 1, 4, 5], where each integer corresponds to a word in the vocabulary.
2. Use of an Embedding Layer:
The second step involves converting these sequences of integers into embedding vectors using an embedding layer in the language processing model.
- Embedding Matrix: An embedding matrix is created where each row represents the embedding vector of a specific word in the vocabulary. This matrix can be initialized randomly or pre-trained from existing models like Word2Vec, GloVe, or FastText.
- Mapping Integers: During training, each integer in the sequence is used to index the embedding matrix and retrieve the corresponding embedding vector. For example, if “cat” is represented by 1, then the embedding vector associated with “cat” will be the first row of the matrix.
- Transformation into Vectors: The sequence of integers is thus transformed into a sequence of embedding vectors. If the phrase “the cat is cute” is represented by [3, 1, 4, 5], it is converted into a sequence of embedding vectors, each with a predefined dimension.
3. Model Training:
The final step involves using these embeddings in a classification or prediction model. During training, the weights of the embedding matrix are adjusted to improve the model’s performance.
- Integration into the Model: The embedding vectors are used as inputs for the NLP model, which can be a recurrent neural network (RNN), a convolutional neural network (CNN), or a transformer.
- Forward Propagation: The embedding vectors pass through the model’s various layers to produce predictions. For example, in a text classification task, the model might predict the category of a document.
- Loss Calculation: The loss (or error) between the model’s predictions and the true labels is calculated.
- Backpropagation: The model adjusts the weights of all its layers, including the embedding matrix, to minimize the loss. This backpropagation process refines the embedding vectors so they better capture the semantic relationships specific to the task.
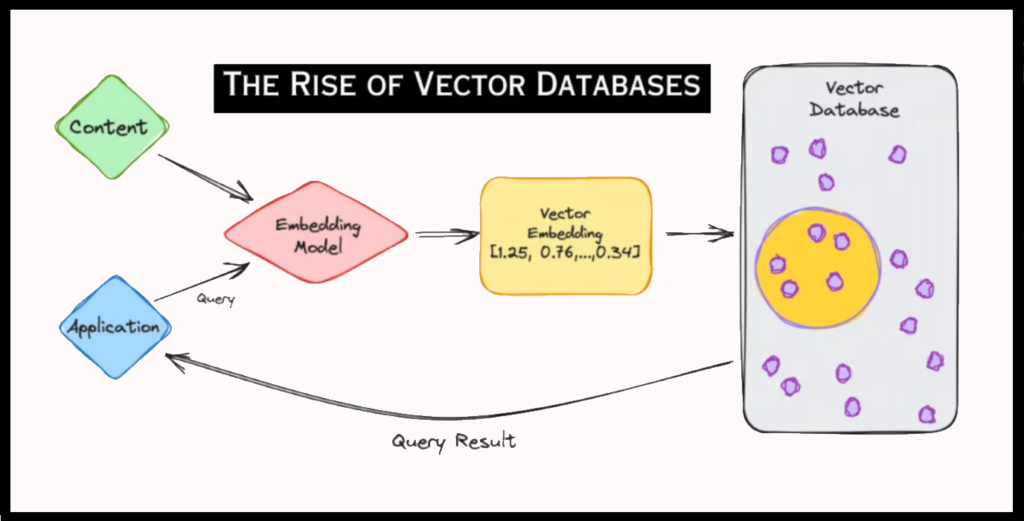
Through these adjustments, the embeddings become increasingly representative of the data and contextual relationships, thereby improving the model’s performance on the given task. A major challenge in their use is their application in real-time information retrieval. To respond effectively to a query, it is necessary to quickly scan and index large amounts of data.
Using Embeddings for Chatbots
Embeddings also enable the creation of more intelligent and relevant chatbots. By integrating embeddings into dialogue systems, it’s possible to provide contextual responses based on previous interactions and available information.
For instance, if a user asks about a refund policy after discussing a specific order, the chatbot can use embeddings to link the question to the order in question and provide an accurate and contextual response.
Moreover, by using a vector database, the chatbot can quickly search and compare question embeddings with those of indexed documents, finding the most relevant answers even in the case of linguistic variations. This approach enables deeper understanding and smoother interaction between the user and the chatbot.
Finally, fine-tuning pre-trained models allows further optimization of AI system performance by adapting embeddings to specific tasks.
Summary
Embedding is a powerful and versatile technique in artificial intelligence. It transforms discrete data into continuous vector representations, facilitating the manipulation and interpretation of information by AI models. Whether in natural language processing, recommendation systems, or information retrieval, embeddings play a crucial role and pave the way for increasingly advanced and efficient applications.
By understanding and mastering embeddings, companies can develop smarter AI systems and respond more effectively to a wide range of queries. At the heart of modern artificial intelligence, there is no doubt that embeddings will continue to be a key area of research and innovation in the years to come.



