

Dans notre blog précédent, nous avons traité des grands modèles de langage (LLM) et de leur utilité en entreprise. Aujourd’hui nous nous intéressons aux modèles de langage plus petits (SML), qui par définition sont des versions allégées des LLM.
Dans le domaine de l’intelligence artificielle, la taille d’un modèle de langage est souvent associée à sa capacité. Les grands modèles de langage, tels que GPT-4, dominent actuellement le secteur et montrent une impressionnante aptitude à comprendre et générer du langage naturel.
Cependant, une tendance émergente révèle que les petits modèles, longtemps relégués au second plan par leurs versions plus volumineuses, gagnent en importance et se positionnent désormais comme des outils performants pour de nombreuses applications d’IA.
Qu’est-ce qu’un petit modèle de langage ?
Un petit modèle de langage est un modèle d’intelligence artificielle conçu pour comprendre et générer du texte de manière efficace en utilisant moins de ressources informatiques. Contrairement à un grand modèle de langage, qui possède des millions ou même des milliards de paramètres et nécessite une énorme puissance de calcul pour traiter de grandes quantités de données, un SLM contient généralement beaucoup moins de paramètres et est conçu pour des tâches plus spécialisées.
Un exemple de SLM est Mistral 7B, un modèle avec seulement 7 milliards de paramètres. Comparé à ChatGPT, Mistral 7B est plus modeste en taille mais peut être très efficace pour des tâches spécifiques comme la classification de texte ou la génération de réponses simples. Son architecture allégée permet une utilisation sur des machines avec des ressources limitées, ce qui est idéal pour les entreprises ayant des contraintes budgétaires ou technologiques.
Les avantages des petits modèles de langage
En raison de leur taille réduite, les SLM sont plus rapides, moins coûteux à déployer, et peuvent être optimisés pour des applications où les ressources sont limitées, comme les appareils mobiles ou les environnements spécifiques à une industrie.
Lorsqu’elles sont construites avec de petits modèles de langage, les applications d’IA générative peuvent fournir un haut niveau de précision avec un minimum de frais généraux. Les modèles d’IA finement ajustés changent donc la donne pour les entreprises en quête de précision, d’efficacité et de sécurité des données, et ce dans de nombreux secteurs :
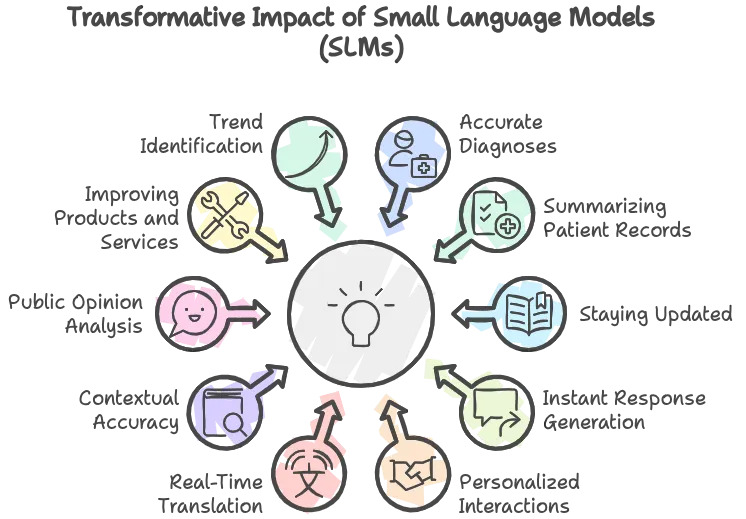
Services informatiques : Le support client est un élément clé pour maintenir la satisfaction et la fidélité des utilisateurs. Les petits modèles de langage peuvent être utilisés pour améliorer l’efficacité du service d’assistance en analysant les tickets de support, les conversations de chat en direct et les courriels des clients pour identifier des motifs récurrents et des problèmes communs.
Gouvernements : Les SLM peuvent analyser de vastes ensembles de données issues de diverses sources, telles que les statistiques démographiques, les rapports de santé publique, les plaintes des citoyens ou les tendances économiques, pour extraire des informations pertinentes et faciliter une prise de décision éclairée.
Secteur bancaire : Les petits modèles de langage peuvent analyser les transactions en temps réel pour identifier les activités suspectes et potentiellement frauduleuses. Ils permettent également d’évaluer les risques de crédit et de détecter des comportements inhabituels, contribuant ainsi à la sécurité et à la stabilité financière.
Santé : Les SLM peuvent aider à analyser les symptômes des patients et à suggérer des diagnostics possibles. Ils peuvent également automatiser la gestion des dossiers médicaux, assurer une meilleure organisation des données patient et faciliter le suivi des traitements.
Commerce : Les petits modèles de langage peuvent analyser des données variées comme les historiques de vente, les tendances du marché et même les avis des clients pour fournir des prévisions de demande plus précises.
L’importance des SLM dans la protection des données
Les SLM prennent une place de plus en plus importante dans la sécurité et la souveraineté des données, notamment parce qu’ils offrent plusieurs avantages par rapport aux grands modèles de langage :
1. Contrôle total sur les données utilisées pour l’entraînement et la personnalisation du modèle
- Confidentialité : Les organisations peuvent s’assurer que les données sensibles ou privées ne quittent jamais leur infrastructure. En utilisant un SLM, les données d’entraînement restent en interne, ce qui réduit le risque de fuite de données ou de violation de la confidentialité.
- Personnalisation : Les SLM permettent une personnalisation fine pour répondre aux besoins d’une entreprise. Cela inclut l’entraînement sur des données internes spécifiques à un domaine, améliorant la pertinence et l’efficacité du modèle tout en garantissant la protection des données sensibles.
2. Déploiement en réseau fermé sans transiter par internet
- Sécurité renforcée : Les données et le modèle restent protégés contre les accès non autorisés, les cyberattaques et les interceptions de données. Le déploiement sur un réseau fermé élimine de nombreux vecteurs d’attaques qui existent lorsque les données doivent transiter par des réseaux externes.
- Souveraineté des données : Les entreprises, notamment celles soumises à des réglementations strictes (comme les gouvernements ou les secteurs sensibles), peuvent conserver un contrôle complet sur l’emplacement et la gestion de leurs données, respectant ainsi les exigences de souveraineté et de conformité locale.
3. Code open source et transparence
- Transparence : Avec un code open source, les organisations peuvent inspecter, auditer et modifier le code du modèle. Cela permet de vérifier que le modèle ne comporte pas de fonctionnalités indésirables ou de failles de sécurité potentielles. Cette transparence est essentielle pour établir la confiance dans le modèle et assurer une utilisation sécurisée.
- Adaptabilité : Les organisations peuvent adapter le code source pour répondre à des besoins spécifiques ou intégrer des mesures de sécurité supplémentaires, telles que des protocoles de cryptage ou des mécanismes de contrôle d’accès renforcés.
4. Efficacité des ressources et coûts réduits
- Réduction des coûts : En raison de leurs exigences moindres en termes de calcul et de stockage, les SLM peuvent être déployés sur des infrastructures locales sans nécessiter d’investissements massifs dans le matériel ou les services cloud. Cela réduit les coûts opérationnels et permet aux organisations de maintenir un contrôle local sur leurs données.
- Efficacité énergétique : Les SLM consomment moins d’énergie, ce qui est bénéfique non seulement pour réduire les coûts, mais aussi pour minimiser l’empreinte carbone de l’entreprise tout en restant conforme aux politiques internes de sécurité des données.
5. Résilience et indépendance technologique
- Autonomie : Les organisations peuvent continuer à utiliser, mettre à jour et améliorer leurs modèles sans être soumises aux changements de politiques ou aux interruptions de service de la part des fournisseurs externes. Cette indépendance est primordiale pour maintenir la continuité des opérations, notamment dans des contextes sensibles ou critiques.
- Souveraineté technologique : En choisissant des solutions open source et en gardant le contrôle sur l’infrastructure, les organisations peuvent éviter le verrouillage technologique (vendor lock-in), ce qui leur donne une plus grande flexibilité pour répondre aux besoins changeants et aux évolutions réglementaires
La puissance des petits modèles linguistiques
Des recherches récentes ont révélé que des modèles disposant de seulement 1 à 10 millions de paramètres peuvent maîtriser des compétences linguistiques élémentaires. Par exemple, un modèle doté de 8 millions de paramètres a obtenu environ 59 % de précision sur le benchmark GLUE en 2023. Ces observations montrent que même des modèles de petite taille peuvent être performants dans certaines tâches de traitement du langage.
Les performances semblent se stabiliser après avoir atteint une certaine échelle, autour de 200 à 300 millions de paramètres, ce qui indique que de nouvelles augmentations de taille produisent des rendements décroissants. Ce plateau représente un point idéal pour les SLM déployables commercialement, équilibrant capacité et efficacité.

L’avantage des SLM dans l’architecture en cascade
L’utilisation des SLM dans une architecture en cascade permet de découper un processus complexe en étapes plus petites. Un peu comme un jeu de briques LEGO, chaque petit modèle de langage agit comme une brique spécialisée qui remplit une tâche précise. En assemblant ces briques les unes après les autres, nous construisons une solution plus grande et plus robuste. Cela permet de traiter les problèmes étape par étape, avec la possibilité d’ajuster ou de remplacer des pièces sans avoir à tout reconstruire.
Contrairement aux grands modèles de langage qui traitent souvent une tâche de manière globale, les petits modèles permettent donc de créer une sorte de chaîne collaborative. Ce découpage modulaire réduit non seulement la charge computationnelle, mais facilite aussi l’ajustement et l’amélioration des différentes parties du système sans nécessiter une révision complète, comme c’est souvent le cas avec les LLM.
LLM vs SLM : Quel modèle choisir ?
Les LLM tels que GPT-4 ou BERT sont des modèles extrêmement complexes, leur taille imposante requiert des ressources informatiques considérables et demande des processeurs puissants, une grande quantité de mémoire vive et un espace de stockage étendu. Par exemple, entraîner un modèle comme GPT-4 a nécessité plusieurs milliers de GPU pendant des semaines. Cela représente un coût très élevé, tant en termes de matériel que de consommation énergétique.
En revanche, les SLM tels que DistilBERT ou Mistral 7B nécessitent beaucoup moins de ressources, ce qui les rend plus abordables et accessibles pour les petites entreprises avec un budget limité. Par exemple, DistilBERT, une version allégée de BERT, peut être déployé sur des ordinateurs standard et même sur certains appareils mobiles.
_________________________________
Les LLM sont conçus pour gérer une grande variété de tâches complexes nécessitant une compréhension approfondie du langage. Ils peuvent effectuer des analyses de sentiments, générer des résumés de texte, traduire des documents, ou encore répondre à des questions en fournissant des réponses contextuelles et détaillées.
Les SLM, quant à eux, sont mieux adaptés aux tâches spécialisées ou à des applications où la rapidité et l’efficacité sont cruciales. Ces modèles sont optimisés pour des contextes spécifiques et peuvent être affinés pour exceller dans des domaines précis
_________________________________
Les LLMs sont des généralistes puissants qui excellent dans des tâches qui requièrent une compréhension large et polyvalente du langage naturel. Ils sont idéaux pour des applications nécessitant une large base de connaissances, comme les systèmes de recommandation, la génération de texte créatif, ou la traduction automatique. Par exemple, DeepL, un service de traduction, utilise des LLM pour fournir des traductions contextuelles précises en plusieurs langues.
Les SLM sont des spécialistes conçus pour des tâches bien définies et plus étroites. Leur capacité à être rapidement ajustés pour des tâches spécifiques les rend parfaits pour des applications comme la classification de texte ou les réponses automatisées dans des systèmes de support client.
_________________________________
Le coût et le temps d’implémentation sont également des facteurs cruciaux dans le choix entre un LLM et un SLM. L’entraînement d’un LLM nécessite non seulement des ressources matérielles et énergétiques considérables, mais aussi un temps significatif pour atteindre un niveau de performance acceptable. De plus, la phase de fine-tuning pour des applications spécifiques peut être longue et coûteuse.
Les SLM, grâce à leur taille plus modeste, sont beaucoup plus rapides à entraîner et à déployer. Ils nécessitent moins de temps pour le fine-tuning, ce qui est idéal pour des entreprises qui souhaitent un retour sur investissement rapide ou qui ont besoin de solutions prêtes à l’emploi dans des délais courts.
Un avenir prometteur pour les SLM
Le choix entre un Large Language Model et un Small Language Model dépend donc de nombreux facteurs qui varient selon les besoins spécifiques de chaque entreprise ou application.
Mais une chose est sûre : l’ère des petits modèles de langage marque un tournant dans le paysage de l’intelligence artificielle. Les entreprises de tous les secteurs peuvent désormais exploiter la précision et l’efficacité des modèles spécifiques à leur secteur d’activité pour obtenir des gains remarquables en termes de précision, de sécurité et de productivité.



